TOON可以节省60%Token?
最近接触的几个本地化智能体应用,线上运行都还比较正常,但是切换到内网后,大模型的推理效果有就前后不一致,大致判断是上下文长度过长,因为推理过程中会涉及到工具查询数据,数据的返回量可能会有差异,导致提示词和问题内容被截断。
经过几番折腾,查阅资料,突然想到了前些天不知在哪里看到了东西:TOON,当即就用来测试了下,效果还可以。
今天就给大家分享下这个格式。
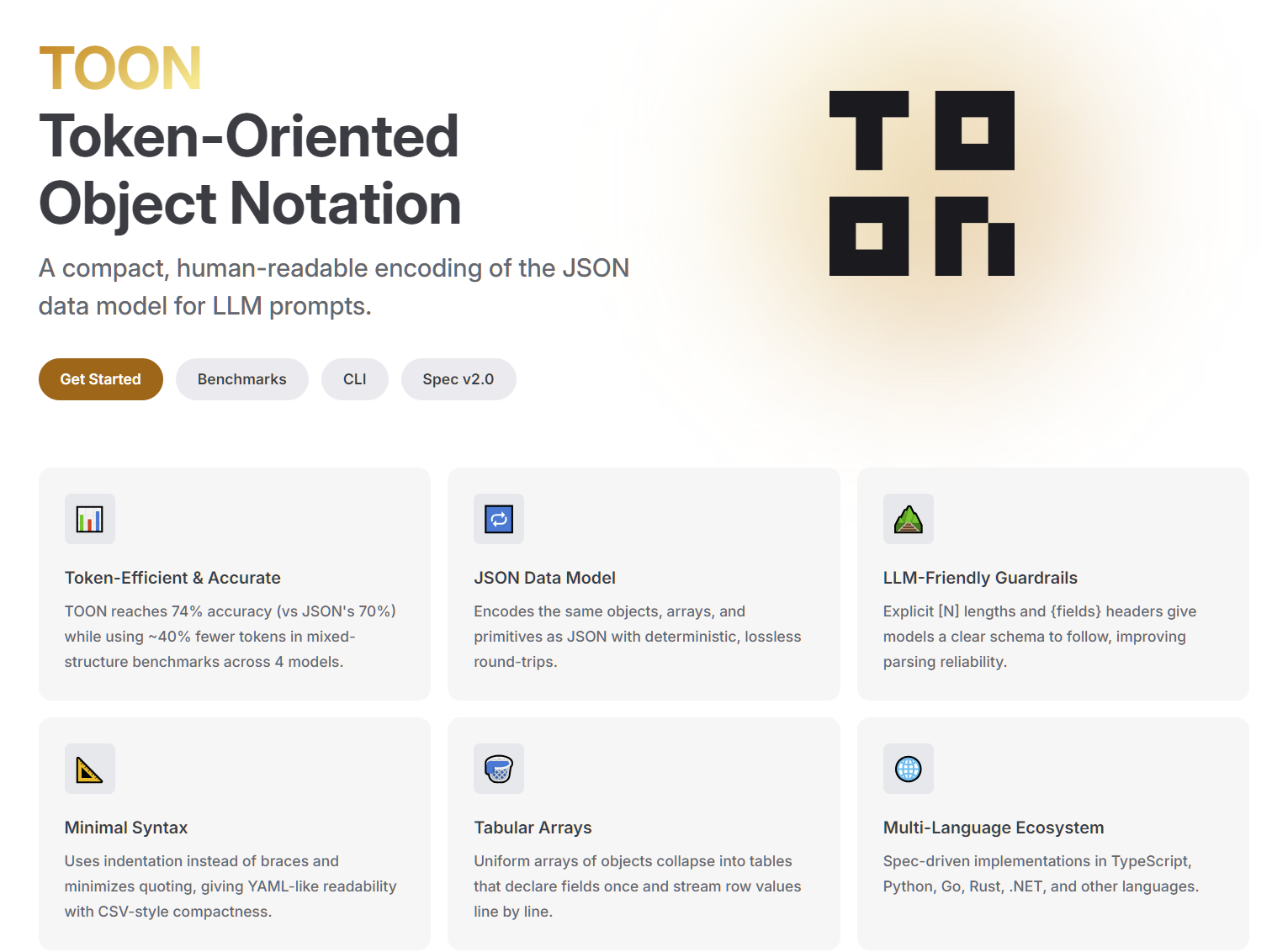
TOON是什么?
先上张对比图让你们感受下暴击👇
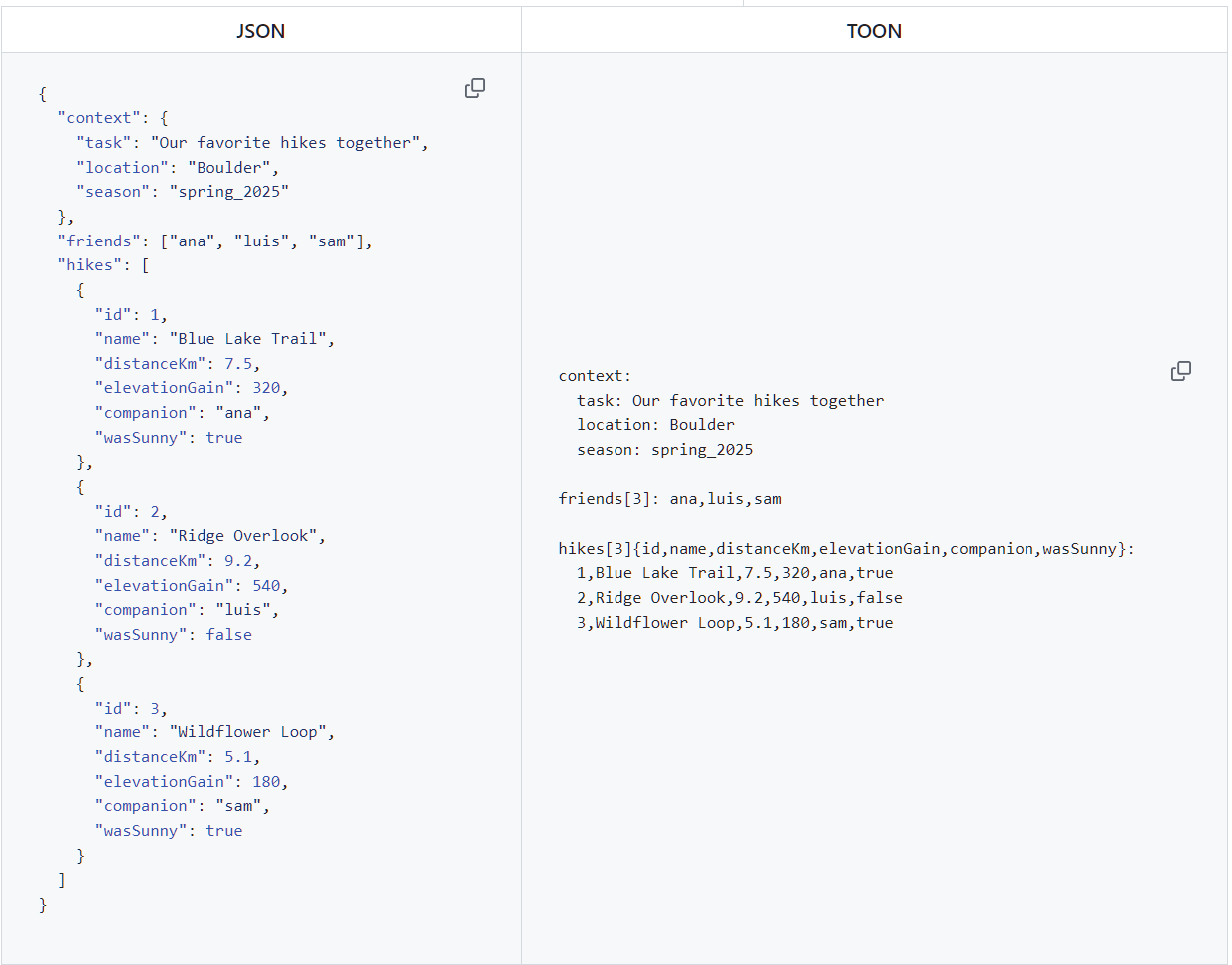
左边是我们祖传的JSON写法,右边是TOON格式。是不是有种"代码减肥成功"的既视感?本质上就是把JSON里那些重复的键名、多余的引号和大括号全扒光了,甚至和CSV格式有点像~
TOON(Text-Oriented Object Notation)是一种轻量级、面向文本的数据交换格式,旨在简洁高效地表示结构化数据。它采用类似于键值对的形式来组织数据,语法简单直观,易于人类阅读和编写,同时也方便计算机解析和生成。
个人阅读后其规范还是和JSON比较相似,据官方介绍"比JSON省30-60% Token",目前规范最新版本3.0,文末附上了官方地址。
本文仅选了部分个人认为比较重点内容进行分享,希望能对TOON能够有个笼统的认识,快速上手。
数据结构
TOON支持的数据模型分为三类:
和JSON的数据类型一致,支持对象(object)和数组(array)两种主要数据结构。对象由一系列键值对组成,键必须是唯一的字符串,值可以是各种数据类型,如字符串、数字、布尔值、对象或数组。数组则是有序的值的集合。
还需要注意:
了解更多见:https://github.com/toon-format/spec/blob/main/SPEC.md#2-data-model
语法规则
规范中描述内容比较多,如果我们仅仅是使用,也可以不用了解太多,使用三方库就可以快速的序列化和反序列化了。
****字符串转义
字符串的引号规则
- 字符串为空时必须使用引号
对象表示格式
格式:key: value,
user:
id: 123
name: "虾搞"🦐是不是和YAML很像____
数组表示格式
数组的格式主要分为两类:
- 原子类型数组:
users[3]{id,name,role}:
1,Alice,admin
2,Bob,user
3,Charlie,user看到没?这样字段名只写一次,数据像表格一样往下排,连逗号都比JSON少一半,这就叫"一次声明,终身受益"。
虾钳划重点
- 表头定乾坤:数组名[N]{字段1,字段2}——N是元素个数,字段用逗号隔开,后面跟个冒号
- 数据裸奔:不用引号不用括号,值直接按顺序排,换行就行
- 缩进表层级:嵌套结构靠缩进来表达
避坑指南 🦠
- 字段顺序不能错:TOON是按位置匹配字段的,少一个逗号都会让模型懵逼
- 嵌套别太深:超过3层嵌套建议拆成多个表,不然缩进能缩进太平洋
- 数字别加引号:上次手贱给ID加了引号,模型直接把123识别成"一百二十三",被测试小姐姐追着打
- 数组长度要诚实:声明了[3]结果只给2条数据,模型会以为你在逗它玩
什么时候用TOON?
其实看完介绍后,发现它和JSON、CSV、YAML都有相似之处,你中有我,我中有你的感觉。可能大家觉得何必又去搞一种新的规范出来,所以我简单整理了下几个格式的比较以及不同场景的分析。
核心特性对比
| 维度 | TOON | JSON | CSV | YAML |
|---|---|---|---|---|
| 语法风格 | 类JSON,支持引号省略 | 严格键值对,强制双引号 | 逗号分隔,无嵌套结构 | 缩进表示层级,支持注释 |
| 数据类型 | 字符串/数字/布尔/对象/数组 | 同TOON,标准更严格 | 仅支持字符串/数字(需手动解析) | 同TOON+日期/二进制等扩展类型 |
| 嵌套支持 | 支持,但3层以上可读性下降 | 原生支持复杂嵌套 | 不支持,需拆表或自定义分隔符 | 天然支持多层嵌套,缩进可视化 |
| 注释功能 | ❌ 不支持 | ❌ 标准不支持(部分解析器扩展) | ❌ 不支持 | ✅ 原生支持#单行注释 |
| 解析效率 | 高(简洁语法减少解析开销) | 高(成熟库支持) | 极高(纯文本无结构解析) | 中(缩进解析较复杂) |
| 应用场景 | 推荐格式 | 关键理由 |
|---|---|---|
| LLM接口调用 | TOON > JSON | TOON平均节省30%-50% Token,例如1000字符JSON可压缩至500字符TOON |
| 配置文件 | YAML > JSON | YAML注释功能提升可维护性,缩进结构更适合人工编辑(如Docker Compose) |
| 表格数据存储 | CSV > TOON | 纯二维数据场景下,CSV存储效率最高(无结构冗余) |
| 深度嵌套数据 | JSON > YAML > TOON | JSON解析性能最优,YAML可读性更好,TOON超过3层嵌套易出错 |
| 跨语言数据交换 | JSON > TOON | JSON生态最完善,所有编程语言均原生支持,TOON需额外解析库 |
虾搞实践
目前toon团队也提供了多种语言的解析库,基本上各类主流语言都有支持:
我搞得几个项目主要是基于python,所以直接使用pip安装解析库:
pip install toon-python
然后引入使用,非常简单:
from toon_format import encode, decode
# Simple object
encode({"name": "Alice", "age": 30})
# name: Alice
# age: 30
# Tabular array (uniform objects)
encode([{"id": 1, "name": "Alice"}, {"id": 2, "name": "Bob"}])
# [2,]{id,name}:
# 1,Alice
# 2,Bob
# Decode back to Python
decode("items[2]: apple,banana")
# {'items': ['apple', 'banana']}将原来的JSON数据全部改为TOON输出,对比了下前后的数据大小变化,确实数据长度大概只有原来的1/5,压缩率达到了80%!确实比较有用👍
总结
其实通过规范定义基本上都可以认识到,相比JSON,TOON少了大量的双引号,这就是能够节约Token的地方。
通过我的几次实验和对比了项目的数据实际情况,TOON尤其在数组对象的数据场景下压缩率较好。因为JSON数组中会重复出现对象的key值,导致Token大量的浪费,甚至在某些地方key比较长的时候,压缩率就更为显著,甚至可能达到90%(比如我项目中,key都是10个字符左右的长度,而值都是简单的数字或几个字符)
最后
如果你比较感兴趣,欢迎去访问官方网站:https://toonformat.dev/了解更多
最后放个官方仓库地址:https://github.com/toon-format/toon,记得点Star~